Целые
Целые являются основными объектами в вычислительной комбинаторике. В различных вычислительных теоретико-числовых исследованиях изучаются сами целые числа, но мы будем использовать их главным образом при подсчете и индексировании. В последнее время установлено, что полезны различные представления. В этой лекции обсудим общий класс позиционных представлений.
Мы будем рассматривать только неотрицательные целые. Кроме того, к любому представлению неотрицательных целых легко присоединить одиночный знаковый двоичный разряд.
Позиционные системы для представления целых чисел очень широко известны, поскольку они встречаются во многих разделах математики, начиная с "новой математики" и кончая углубленным курсом теории чисел. В системе счисления с основанием

 |
(2.1) |
в которой каждое






что принято выражать следующим образом:

На протяжении истории использовались различные значения






Единственность этого представления можно доказать методом от противного. Числа




Если



и поскольку
 |
(2.2) |
что невозможно. Таким образом, мы должны иметь



Следовательно, число

имеет два различных представления, что противоречит предположению, что

Для доказательства того, что каждое положительное целое имеет представление по основанию
Алгоритм 1. Преобразование числа

Он строит последовательность


Важным обобщением систем счисления с основанием


где теперь каждое





Смешанные системы счисления могут вначале показаться странными, но в действительности в повседневной жизни они встречаются почти так же часто, как и десятичные.
Пример. Рассмотрим нашу систему измерения времени: секунды, минуты, часы, дни недели и годы. Это - в точности смешанная система с

Представление целого



Алгоритм 2. Преобразование числа


Последовательности
Бесконечная последовательность

формально определяется как функция



как функцию, областью определения которой является множество

 |
(2.3) |

а перестановка

представляет собой пример конечной последовательности.
В комбинаторных алгоритмах часто приходится встречаться с представлениями конечных последовательностей (или начальных сегментов бесконечных последовательностей) и операциями над ними.
Различные способы представлений
Последовательное распределение. С вычислительной точки зрения простейшим представлением конечной последовательности является список ее членов, расположенных по порядку в последовательных ячейках памяти.
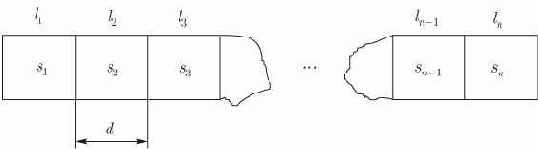
Рис. 2.1.
Последовательное распределение последовательности


Так,







Описанное выше представление последовательности имеет ряд преимуществ. Во-первых, оно легко осуществимо и требует небольших расходов в смысле памяти. Кроме того, оно полезно и потому, что существует простое соотношение между



Это соотношение позволяет организовать прямой доступ к любому элементу последовательности. Наконец, последовательное представление имеет достаточно широкий диапазон и включает в себя в качестве специального случая представление многомерных массивов.
Например, чтобы представить массив размером

 |
(2.4) |
будем рассматривать его как последовательность







ячейка для


Это представление известно как построчная запись матрицы; постолбцовая запись получается, если (2.4) рассматривать как последовательность


Последовательное распределение, наряду с преимуществами, имеет значительные недостатки. Например, такое представление становится неудобным, если требуется изменить последовательность путем включения новых и исключения имеющихся там элементов. Включение между


Характеристические векторы. Важной разновидностью последовательного распределения является случай, когда такому представлению подвергается последовательность некоторой основной последовательности

Например, характеристический вектор начального сегмента последовательности (2.3)

характеристический вектор для простых чисел:

Здесь основной последовательностью является последовательность целых положительных чисел. В ЭВМ с 32-разрядными словами для запоминания простых чисел, меньших






Характеристические векторы полезны в ряде случаев. Их полезность вытекает из их компактности, существования простого фиксированного соотношения между
Главное неудобство характеристических векторов состоит в том, что они не экономичны. Исключение составляют "плотные" последовательности последовательностей






в качестве основных объектов допускает
Большинство вычислительных устройств в качестве основных объектов допускает только двоичные наборы, целые и символы, поэтому, прежде чем работать с более сложными объектами, их необходимо представить двоичными наборами, целыми или символами. Например, числа с плавающей запятой кодируются целыми - мантиссой и порядком этого числа, но такое кодирование обычно незаметно для пользователя. В противоположность этому, рассмотренные во второй и третьей лекции способы кодирования объектов (множества, последовательности, деревья) всегда адресованы пользователю.
Любой заданный класс объектов может иметь несколько возможных представлений, и выбор наилучшего из них решающим образом зависит от того, каким образом объект будет использован, а также от типа производимых над ним операций. Поэтому рассмотрим не только свойства самих представлений, но также и некоторые приложения.
Программы
Программа 1. Создание списка.
// Алгоритм реализован на языке программирования Turbo-C++. #include <stdio.h> #include <conio.h> #include <dos.h>
struct List{int i; List*next; }; List*head=NULL;
void Hed(int i) {if(head==NULL){head=new List; head->i=1; head->next=NULL; }else { struct List*p,*p1; p=head; while(p->next!=NULL) p=p->next;
p1=new List; p1->i=i; p1->next=NULL; p->next=p1; } }
int s=0;
void Print(List*p) {cprintf(" %d",p->i); if(p->next!=NULL)Print(p->next); }
void delist() {List*p; while(head!=NULL) {p=head; head=head->next; delete(p); } } void Vstavka(int i1,int c) {List*p=head,*p1; while(p->i!=i1) p=p->next; p1=new List; p1->i=c; p1->next=p->next; p->next=p1; }
void main() { clrscr(); for(int i=1;i<=10;i++) Hed(i); textcolor(12); Print(head); textcolor(1); Vstavka(10,11); printf("\n"); Print(head); textcolor(11); Vstavka(3,12); printf("\n"); Print(head); textcolor(14); Vstavka(5,13); printf("\n"); Print(head); delist(); getch(); }
Программа 2. Создание стека и работа со стеком.
//Работа со стеком // Алгоритм реализован на языке программирования Turbo-C++. #include <stdio.h> #include <dos.h> #include <iostream.h> #include <PROCESS.H> #include <STDLIB.H> #include <conio.H> #define max_size 200 // char s[max_size]; //компоненты стека int s[max_size]; int next=0; // позиция стека int Empty() { return next==0; } int Full() { return next==max_size; } void Push() { if (next==max_size) { cout <<"Ошибка: стек полон"<<endl;}
else { next++;cout <<"Добавлен"<<endl; cout <<"Что поместить в стек?"<<endl; cin <<s[next-1]; } } void OUTst() {int i=0; if (next==0) { cout <<"Cтек пуст"<<endl;}
else { for(i=0;i <next;i++) cout <<s[i] <<"" <<endl; } } void Clear() { next=0; } Poz() { return next; } void Del() { int a; if (next==0) cout <<"Ошибка: стек пуст" <<endl; else {next--;cout <<"Удален" <<endl;} } void menu(){ cout <<"0: распечатать стек" <<endl; cout <<"1: добавить в стек" <<endl; cout <<"2: удалить из стека" <<endl; cout <<"3: узнать номер позиции в стеке" <<endl; cout <<"4: узнать, пуст ли стек" <<endl; cout <<"5: узнать, полон ли стек" <<endl; cout <<"6: очистить стек" <<endl; cout <<"7: выход" <<endl; } main() { char c; clrscr(); textcolor(11); do { menu(); cin"c; clrscr(); switch (c) { case "0":OUTst();getch();break; case "1":Push();break; case "2":Del();getch();break; case "3":cout <<"Hомер" <<Poz() <<endl;getch();break; case "4":if (Empty()==1) cout <<"Пуст" <<endl; else cout <<"Hе пуст" <<endl;getch();break; case '5':if (Full()==1)cout <<"Полн" <<endl; else cout <<"Hе полон" <<endl;getch();break; case '6':Clear();cout <<"Стек очищен" <<endl;getch();break; case '7':exit(1); } delay(200); } while (c!=7); return 0; }
Разновидности связанных списков
Тривиальной модификацией связанного списка, изображенного на рис 3.2, будет следующее несколько более гибкое представление последовательности: если


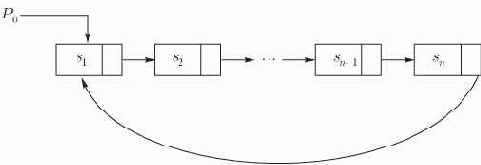
Рис. 3.5. Циклический список
Еще большая гибкость достигается, если использовать дважды связанный список, когда каждый элемент



без предварительного знания его предшественника. Если есть необходимость, дважды связанный список очевидным образом можно сделать циклическим.

Рис. 3.6. Дважды связанный список
Стеки и очередь
В комбинаторных алгоритмах особую важность представляют две структуры данных, основанные на динамических последовательностях, т.е. последовательностях, которые изменяются вследствие включения новых и исключения имеющихся элементов. В обоих случаях операции включения и исключения, которым подвергается последовательность, имеют ограниченный вид: они производятся только в концах последовательности. Стек есть последовательность, у которой все включения и исключения происходят только в ее правом конце, называемом вершиной стека (соответственно, левый конец последовательности называется основанием). Таким образом, элементы включаются в стек и исключаются из него в соответствии с правилом "Первым пришел - последним ушел". Очередь - это последовательность, в которой все включения производятся на правом конце списка (в конце очереди), в то время как все исключения производятся на левом конце (в начале очереди). В противоположность стеку очередь оперирует в режиме "Первым пришел - первым ушел".
Стеки и очереди имеют важное значение. Для выполнения какой-либо определенной задачи может потребоваться выполнение ряда подзадач. Каждая подзадача может также привести к другим требующим выполнения подзадачам. И стеки, и очереди являются механизмом, посредством которого запоминаются подзадачи, подлежащие выполнению, а также порядок, в котором они должны быть выполнены. В некоторых случаях порядок таков: "Первым пришел - последним ушел"; тогда удобно использовать стеки. Если порядок подчиняется правилу "Первым пришел - первым ушел", то подходящим инструментом являются очереди.
Связанное распределение
В лекции 11 даны примеры и программные реализации списков, стеков и очередей. Неудобство включения и исключения элементов при последовательном распределении происходит из-за того, что порядок следования элементов задается неявно требованием, чтобы смежные элементы последовательности находились в смежных ячейках памяти. В результате многие элементы последовательности во время включения или исключения должны передвигаться. Если это требование опущено, то можно выполнить операции включения и исключения без того, чтобы передвигать элементы последовательности. При связанном распределении последовательности (связанном списке) каждому
поставлен в соответствии указатель (ссылка)






Рис. 3.1.
Здесь каждый узел состоит из двух полей. Под узлом понимается одно или несколько последовательных слов в памяти машины, которые выступают как единое целое и разделены на части, именуемые полями. В поле


Linked list - список с использованием указателей: список, в котором каждый элемент содержит указатель на следующий элемент или два указателя - на следующий и предыдущий. Поскольку для





Рис. 3.2. Другой, более употребительный, способ представления списка
Связанное представление последовательностей облегчает операции включения элемента после некоторого



после такой операции элемента





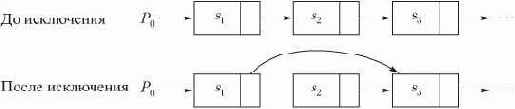
Рис. 3.3. Исключение элемента из связанного списка
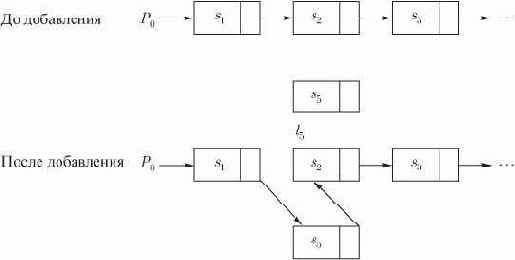
Рис. 3.4. Включение элемента в связанный список
Использование связанного представления предполагает существование некоторого механизма, который по мере надобности поставляет новые ячейки и собирает старые ячейки, когда они освобождаются, но эта проблема выходит за рамки нашего курса.
Будем предполагать, с целью использования в различных алгоритмах, существование операции порождения ячейки get_cell; если эта операция присутствует в правой части оператора присваивания, то она дает адрес (место) новой неиспользованной ячейки памяти. Таким образом, чтобы добавить элемент
Недостаток при связанном распределении - приходится тратить память на указатели

Модифицированный список
Задача 1. Создать список, элементами которого являются числа: 1 2 3 4 5 6 7 8 9. Вывести список на экран терминала. Включить в связанный список элемент 2005 после каждого элемента, который делится на 3. Модифицированный список вывести на экран терминала.
Задача 2. Очередью с приоритетом называется линейный список, который оперирует в режиме "первым включается - с высшим приоритетом исключается"; иными словами, каждому элементу очереди сопоставлено некоторое число - приоритет. Включения производятся в конец очереди, а исключения - в любом месте очереди, поскольку исключаемый элемент - это всегда элемент с высшим приоритетом. Нужно описать алгоритм (и его реализацию) включения и исключения для очередей с приоритетом.
Деревья
Конечное корневое дерево


поддеревьев

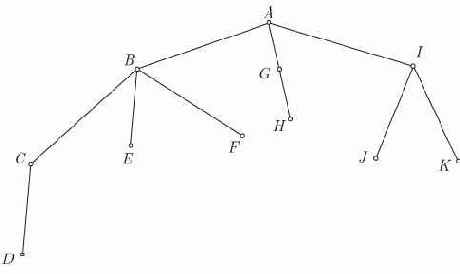
Рис. 4.1.
Дерево с 11 узлами, помеченными буквами от



В первой лекции уже было использовано дерево - при изучении необходимого числа взвешиваний в задаче о фальшивой монете с
В описании соотношений между узлами дерева используем терминологию, принятую в генеалогических деревьях. Так, говорят, что в дереве или поддереве все узлы являются потомками его корня, и наоборот, корень есть предок всех своих потомков. Корень именуют отцом корней его поддеревьев, которые в свою очередь будут сыновьями корня. Например, на рис. 4.1 узел




Все рассматриваемые нами деревья будут упорядочены, то есть для них будет важен относительный порядок поддеревьев каждого узла. Таким образом, деревья считаются различными.
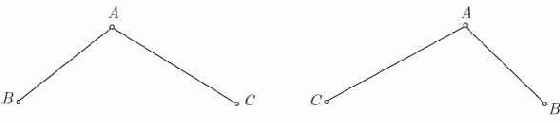
Рис. 4.2. Различные деревья
Определим лес как упорядоченное множество деревьев; в связи с этим можно перефразировать определение дерева: дерево есть непустое множество узлов, такое, что существует один выделенный узел, называемый корнем дерева, а оставшиеся узлы образуют лес с
поддеревьями корня. Важной разновидностью корневых деревьев является класс бинарных деревьев. Бинарное дерево


Бинарные деревья не являются подмножеством множества деревьев, они полностью отличаются по своей структуре, поскольку два следующих рисунка не изображают одно и то же бинарное дерево.

Рис. 4.3. Различные бинарные деревья
Как деревья, однако, они не отличаются от дерева, изображенного на рис. 4.4.

Рис. 4.4. Не бинарное дерево
Различие между деревом и бинарным деревом состоит в том, что дерево не может быть пустым, а каждый узел дерева может иметь произвольное число поддеревьев; в то же время, бинарное дерево может быть пустым. Каждая из вершин бинарного дерева может иметь 0, 1 или 2 поддерева, и существует различие между левым и правым поддеревьями.
Длина путей
Деревья можно использовать не только как способ представления структуры данных, но также как средство для анализа поведения определенных алгоритмов. В связи с этим возникает потребность в количественных измерениях различных характеристик деревьев и, в частности, бинарных деревьев.
Наиболее важные количественные характеристики деревьев связаны с уровнями узлов. Уровень




Другими словами, высота дерева есть максимальное число ребер, образующих путь от корня к листу дерева.
Представления
Почти все машинные представления деревьев основаны на связанных распределениях. Каждый узел состоит из поля

Такое представление полезно, если необходимо подниматься по дереву от потомков к предкам. Такая операция встречается довольно редко. Чаще требуется опуститься по дереву от предков к потомкам.
Представление дерева (или леса) с использованием указателей, ведущих от предков к потомкам, довольно сложно, поскольку узел, имея не более чем одного отца, может в то же время иметь произвольно много сыновей. Другими словами, при таком представлении узлы должны различаться по размеру, что является определенным неудобством. Один из путей обхода этой трудности состоит в том, чтобы определить соответствие между деревьями и бинарными деревьями, поскольку бинарные деревья легко представить узлами фиксированного размера.
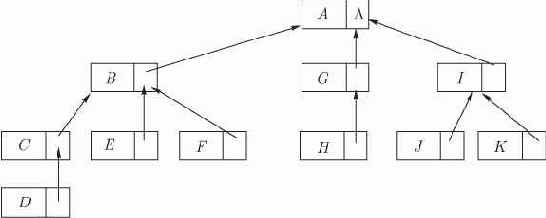
Рис. 4.5. Дерево из рис. 4.1, представленное с помощью узлов с полем
Каждый узел в этом случае имеет три поля:


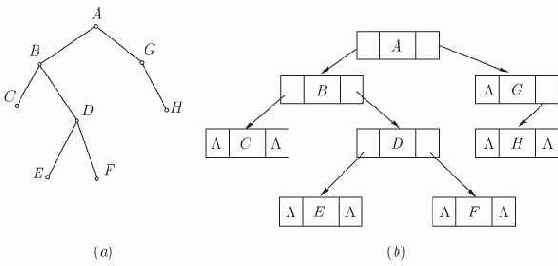
Рис. 4.6. Бинарное дерево и его представление с помощью узлов с тремя полями
Можно представлять деревья как бинарные, используя узлы фиксированного размера, представляя каждый узел леса в виде узла, состоящего из полей
предназначается для указания самого левого сына данного узла, а поле
Программa
Программа 1. Обход бинарного дерева в глубину
//Обход ориентированных графов - поиск в глубину - //обобщение обхода дерева в прямом порядке #include <stdio.h> #include <string.h> #include <conio.h> #include <stdlib.h>
int matr_sm[50][50]; int mark[50]; int n;
void vvod () {int v1,v2; printf("Введите кол-во вершин в графе: "); do { scanf("%d",&n); if (n>51) printf("Ошибка!! Введите кол-во вершин в графе: "); } while (n>51);
for (int i=0;i <50;i++) for (int j=0;j <50;j++) matr_sm[i][j]=0;
printf("\nВведите связанные вершины : \n"); do { scanf("%d ",&v1); if (v1>n) //исходящая вершина { printf("ОШИБКА ВВОДА !!!!!!!!!"); abort(); } if (v1==0){break;} // конец ввода scanf(" %d ",&v2); if (v2>n) // входящая вершина { printf("ОШИБКА ВВОДА !!!!!!!!!"); abort(); } if (v2==0){break;} //конец ввода matr_sm[v2-1][v1-1]=1; } while(1); }
void vivod() { for (int j=0;j <n;j++) { for (int i=0;i<n;i++) printf("%d ",matr_sm[j][i]); printf("\n"); } }
void dfs(int v) { int w; mark[v]=1; //посетили printf("%i ",v+1); //и выдали на экран for (w=0;w<n;w++) if (matr_sm[v][w]==1); else if (mark[w]==0) dfs(w); }
void main() { clrscr(); vvod(); // printf("\n"); printf("МАТРИЦА СМЕЖНОСТИ\n"); // vivod();
printf("\n РЕЗУЛЬТАТ ПОИСКА В ГЛУБИНУ \n"); for (int v=0;v<50;v++) mark[v]=0; for (v=0;v<n;v++) //если вершина не посещалась, то посетить if (mark[v]==0) dfs(v);
getch(); }
Прохождения
Во многих приложениях необходимо пройти лес, заходя в узлы, то есть обрабатывая их некоторым систематическим образом. Посещение каждого узла может быть связано с простой операцией, такой как печать содержимого, или со сложной, такой как вычисление функции. Будем предполагать, что при посещении узла структура леса не меняется. Рассмотрим четыре основных способа прохождения леса: в глубину, снизу вверх, в горизонтальном порядке и для бинарных деревьев - в симметричном порядке.
При прохождении в глубину, известном также как прохождение в прямом порядке, узлы леса проходятся в соответствии со следующей рекурсивной процедурой:
Посетить корень первого дерева.пройти в глубину поддерева первого дерева (если оно есть).Пройти в глубину оставшиеся деревья, если они есть.
Например, для леса, показанного на рис. 4.7, узлы будут проходиться в следующем порядке:

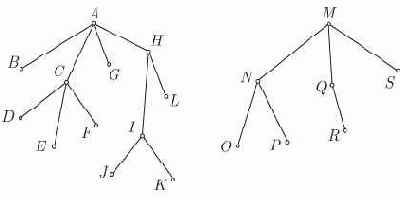
Рис. 4.7. Лес
Название "в глубину" отражает тот факт, что после посещения некоторого узла мы продолжаем прохождение в глубь дерева всякий раз, когда это возможно. Такой порядок особенно полезен в процедурах поиска.
Для бинарных деревьев эта процедура упрощается и выглядит следующим образом.
Посетить корень.Пройти в глубину левое поддеревоПройти в глубину правое поддерево.
Прохождение снизу вверх, известное также как обратный порядок или концевой порядок, осуществляется согласно следующей рекурсивной процедуре:
Пройти снизу вверх поддеревья первого дерева, если они есть.Посетить корень первого дерева.Пройти снизу вверх оставшиеся деревья, если они есть.
Название "снизу вверх" связано с тем, что в момент посещения произвольного узла его потомки оказываются уже пройденными. Такой порядок прохождения полезен, в частности, потому, что он позволяет вычислять рекурсивно определенные функции на лесах. При этом порядке прохождения узлы леса, показанного на рис. 4.7, проходятся в такой последовательности:

Пройти снизу вверх левое дерево.Пройти снизу вверх правое дерево.Посетить корень.
Симметричный порядок для бинарных деревьев определяется рекурсивно следующим образом:
Пройти в симметричном порядке левое поддерево.Посетить корень.Пройти в симметричном порядке правое поддерево.
Такой способ прохождения известен также как лексикографический порядок или внутренний порядок. Заметим, что прохождение леса снизу вверх эквивалентно прохождению в симметричном порядке бинарного дерева, соответствующего этому лесу (при естественном соответствии).
Сравнивая рекурсивные процедуры прохождения бинарных деревьев в глубину, снизу вверх и в симметричном порядке, можно обнаружить их значительное сходство:
| посетить корень | левое поддерево | левое поддерево |
| левое поддерево | посетить корень | правое поддерево |
| правое поддерево | правое поддерево | посетить корень |
Горизонтальный порядок прохождения. При таком способе узлы леса проходятся слева направо, уровень за уровнем от корня вниз. Таким образом, в соответствии с этой процедурой узлы леса, показанного на рис.4.7, будут проходиться в следующем порядке:

Построить алгоритм обхода
Задача 1. Построить алгоритм обхода бинарного дерева (см. рис. 4.6,(а)) в глубину.
Число сочетаний
Рассмотрим подмножества множества, состоящего из пяти элементов, и подсчитаем их число. При этом записывать подмножества будем не с помощью букв, как обычно, а в виде последовательностей длиной пять, составленных из нулей и единиц. Каждая из единиц указывает на наличие в подмножестве соответствующего элемента. Например, подмножества, содержащие один элемент, будут изображаться следующими последовательностями: 10000, 01000, 00100, 00010, 00001. Пустое подмножество


Вообще, число сочетаний из

Деревья и перестановки из n элементов
С помощью леса можно представить перестановки из

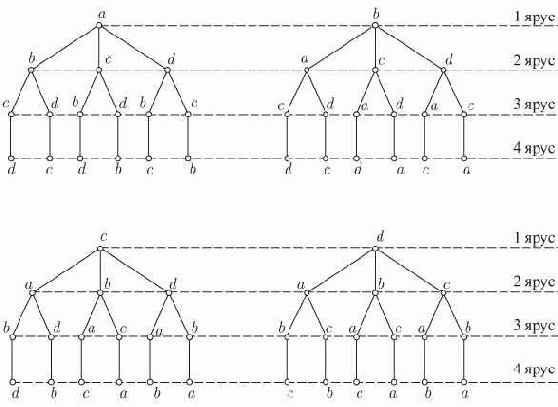
Рис. 5.1. Всевозможные перестановки прочитываются по этой схеме от корневой до висячей вершины соответствующего дерева. Ярус показывает номер места, на котором расположен элемент. Число висячих вершин леса равно числу перестановок
Комбинаторные задачи теории информации
Информация - сведения, неизвестные до их получения, или данные, или значения, приписанные данным.
Теория информации - математическая дисциплина, изучающая количественные свойства информации.
Задачу, похожую на только что решенную, приходится решать в теории информации. Предположим, что сообщение передается с помощью сигналов нескольких типов. Длительность передачи сигнала первого типа равна



Задача 6. Сколько различных сообщений можно передать с помощью этих сигналов за
Обозначим число сообщений, которые можно передать за время

 |
(5.8) |



Разные статистики
Задачи о раскладке предметов по ящикам весьма важны для статистической физики. Эта наука изучает, как распределяются по своим свойствам физические частицы; например, какая часть молекул данного газа имеет при данной температуре ту или иную скорость. При этом множество всех возможных состояний распределяют на большое число

Вопрос о том, какой статистике подчиняются те или иные частицы, зависит от вида этих частиц. В классической статистической физике, созданной Максвеллом и Больцманом, частицы считаются различимыми друг от друга. Такой статистике подчиняются, например, молекулы газа. Известно, что

Оказалось, что этой статистике подчиняются не все физические объекты. Фотоны, атомные ядра и атомы, содержащие четное число элементарных частиц, подчиняются иной статистике, разработанной Эйнштейном и индийским ученым Бозе. В статистике Бозе-Эйнштейна частицы считаются неразличимыми друг от друга. Поэтому имеет значение лишь то, сколько частиц попало в ту или иную ячейку, а не то, какие именно частицы туда попали.
Однако для многих частиц, например таких как электроны, протоны и нейтроны, не годится и статистика Бозе-Эйнштейна. Для них в каждой ячейке может находится не более одной частицы, причем различные распределения, удовлетворяющие указанному условию, имеют равную вероятность. В этом случае может быть

В задачах, которые мы сейчас
В задачах, которые мы сейчас рассмотрим, элементы делятся на группы, и надо найти все способы такого раздела. При этом могут встретиться различные случаи. Иногда существенную роль играет порядок элементов в группах: например, когда сигнальщик вывешивает сигнальные флаги на нескольких мачтах, то для него важно не только то, на какой мачте окажется тот или иной флаг, но и то, в каком порядке эти флаги развешиваются. В других же случаях порядок элементов в группах никакой роли не играет. Когда игрок в домино выбирает кости из кучи, ему безразлично, в каком порядке они придут, а важен лишь окончательный результат.
Отличаются задачи и по тому, играет ли роль порядок самих групп. При игре в домино игроки сидят в определенном порядке, и важно не только то, как разделились кости, но и то, кому какие кости достались. Если раскладывать фотографии по одинаковым конвертам, чтобы разослать их, то существенно, как распределяются фотографии по конвертам, но порядок самих конвертов совершенно несущественен.
Играет роль и то, различаем ли мы между собой сами элементы или нет, а также различаем ли между собой группы, на которые делятся элементы. Наконец, в одних задачах некоторые группы могут оказаться пустыми, то есть не содержащими ни одного элемента, а в других такие группы недопустимы. В соответствии со всем сказанным возникает целый ряд различных комбинаторных задач на разбиение.
Сколькими способами можно сделать такое
Общая постановка этих задач:
Задач 1. Раскладка по ящикам
Даны




Число различных раскладок по ящикам равно

Задача 2. Перестановки с повторением.
Имеются предметы


 | (5.1) |


Перестановки элементов первого типа, второго типа и так далее можно делать независимо друг от друга. Поэтому элементы перестановки 5.1. можно переставлять друг с другом


 | (5.2) |
Пользуясь формулой 5.2, можно ответить на вопрос: сколько перестановок можно сделать из букв слова "Миссисипи"? Здесь у нас одна буква "м", четыре буквы "и", три буквы "с" и одна буква "п", а всего 9 букв. Значит, по формуле 5.2 число перестановок равно

Каждой перестановке соответствует распределение номеров мест на
В рассмотренных задачах мы не учитывали порядок, в котором расположены элементы каждой части. В некоторых задачах этот порядок надо учитывать.
Задача 3. Флаги на мачтах.
Имеется
Каждый способ развешивания флагов можно осуществить в два этапа. На первом этапе мы переставляем всеми возможными способами данные

 | (5.3) |

Задачи на разбиение чисел
Теперь мы переходим к задачам, в которых все разделяемые предметы совершенно одинаковы. В этом случае можно говорить не о разделении предметов, а о разбиении натуральных чисел на слагаемые (которые, конечно, тоже должны быть натуральными числами).
Здесь возникает много различных задач. В одних задачах учитывается порядок слагаемых, в других - нет.
Задача 4. Отправка бандероли.
За пересылку бандероли надо уплатить 18 рублей. Сколькими способами можно оплатить ее марками стоимостью 4, 6, и 10 рублей, если два способа, отличающиеся порядком марок, считаются различными (запас марок различного достоинства считаем неограниченным)?
Обозначим через

 |
(5.4) |


Точно так же доказывается, что число комбинаций, оканчивающихся на на шестирублевую марку, равно


Соотношение 5.4 позволяет свести задачу о наклеивании марок на сумму


Используя значения



















Точно так же получаем значение



Задача 5.Общая задача о наклейке марок.
Разобранная задача является частным случаем следующей общей задачи:
Имеются марки достоинством в


В этом случае число
 | (5.5) |



Рассмотрим частный случай этой задачи, когда




 | (5.6) |





 | (5.7) |







| 5 = 5 | 5 = 3 + 1 + 1 | 5 = 1 + 2 + 2 |
| 5 = 4 + 1 | 5 = 1 + 3+ 1 | 5 = 2 + 1 + 1 + 1 |
| 5 = 1 + 4 | 5 = 1 + 1 + 3 | 5 = 1 + 2 + 1 + 1 |
| 5 = 2 + 3 | 5 = 2 + 2 + 1 | 5 = 1 + 1 + 2 + 1 |
| 5 = 3 + 2 | 5 = 2 + 1 + 2 | 5 = 1 + 1 + 1 + 2 |
| 5 = 1 + 1 + 1 + 1 + 1 |
Формула включений и исключений
Пусть имеется







 |
(6.3) |
Здесь алгебраическая сумма распространена на все комбинации свойств




Множества и мультимножества
Не существует формального определения множества; считается что это понятие первичное и не определяется. Так, можно говорить, что множество есть объединение различных элементов, но при этом мы оставляем неопределяемыми понятия "объединение" и "элементы". Дадим следующее определение множеству: множество - это неупорядоченная совокупность различных объектов или структура данных, используемая для представления множества. Мультимножество есть объединение не обязательно различных элементов; его можно считать множеством, в котором каждому элементу поставлено в соответствие положительное целое число, называемое кратностью.
Конечное множество


где




Здесь все


Наиболее общими операциями на множествах и мультимножествах являются операции объединения и пересечения. Для множеств эти операции будем обозначать




Как и для последовательностей, наилучший метод представления множеств или мультимножеств существенно зависит от операций, которые выполняются над ними. Предположим, например, что имеем дело с непересекающимися подмножествами множества

Таким образом, в любой момент времени имеем разбиение
С целью идентификации считаем, что каждое из непересекающихся подмножеств множества

разбитое на четыре непересекающихся подмножества
 | (6.1) |
следующего вида:

Именем множества



на
 | (6.2) |
Для реализации операций и объединения, и отыскания опишем процедуры (операции)



и

выдает имя множества, содержащего



Предположим, что мы имеем


Такой структурой данных является представление в виде леса с указателями отца, как показано на рис. 4.5 лекции 4. Каждый элемент
Рис. 6.1. Представление разбиения
При таком представлении процедура (операция)
После


объединений, откуда


Если операция

В этом случае, если


Примеры программы
Программа 1. Решето Эратосфена.
{В примере, иллюстрирующем работу с множествами, реализуется алгоритм выделения из первой сотни натуральных чисел всех простых чисел. В основе алгоритма лежит прием "решета Эратосфена". Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt; Const N=100; {количество элементов исходного множества} Type SetN=set of 1..N; var n1, next, I : word; {вспомогательные переменные } BeginSet, {исходное множество } PrimerSet: SetN; {множество простых чисел } Begin Clrscr; {почистить экран} BeginSet:=[2..N]; {создать исходное множество} PrimerSet:=[1]; {первое простое число} next:=2; {следующее простое число} while BeginSet <> [ ] do {начало основного цикла} begin n1:=next; {n1-число, кратное очередному простому (next)} while n1<=N do {цикл удаления из исходного множества непростых чисел} begin BeginSet:=BeginSet-[n1]; n1:=n1+next {следующее кратное} end; {конец цикла удаления} repeat {получить следующее простое число, которое есть первое не вычеркнутое из исходного множества} inc(next) until(next in BeginSet) or (next > N) end; {конец основного цикла} {вывод результата} textcolor(15); {задание цвета} for I:=1 to N do if i in PrimerSet then write(I:8); readlen; end.
Программа 2. Простые числа в порядке убывания от 200.
{Находит и пишет все простые числа в порядке убывания от 2 до 200. Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt; const n=197; var
i,q,w,e,r,t:integer; prost:array[1..n] of integer;
begin clrscr; e:=1; r:=0; for q:=1 to n do begin r:=0; for w:=2 to n-1 do if (q<>w) and (q mod w = 0) then r:=1; {prost[e]:=q; e:=e+1;}
if r=0 then begin{begin write(q,' ');}
prost[e]:=q; e:=e+1; end; end;
for i:=e downto 2 do begin write (prost[i],' '); if wherex>70 then writeln;
end; readln; end.
Программа 3. Поиск литер в строке.
{Поиск числа вхождений в данную сроку литер a, c, e, h. Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt; type liter_set = set of char;
var c:integer; let: liter_set; a:char;
begin clrscr; let:=['a','c','e','h'];
repeat a:=readkey; write(a); if a in let then c:=c+1; until a = '.'; writeln; writeln('Общее число вхожений литер a,c,e,h в вашу запись:',c); readln;
end.
Решето Эратосфена
Одной из самых больших загадок математики является расположение простых чисел в ряду всех натуральных чисел. Иногда два простых числа идут через одно, (например, 17 и 19, 29 и 31), а иногда подряд идет миллион составных чисел. Сейчас ученые знают уже довольно много о том, сколько простых чисел содержится среди
Эратосфен занимался самыми различными вопросами - ему принадлежат интересные исследования в области математики, астрономии и других наук. Впрочем, такая разносторонность привела его к некоторой поверхностности. Современники несколько иронически называли Эратосфена "во всем второй": второй математик после Евклида, второй астроном после Гиппарха и т.д.
В математике Эратосфена интересовал как раз вопрос о том, как найти все простые числа среди натуральных чисел от 1 до
Подсчитаем, сколько останется чисел в первой сотне, если мы вычеркнем по методу Эратосфена числа, делящиеся на 2, 3 и 5. Иными словами, поставим такой вопрос: сколько чисел в первой сотне не делится ни на одно из чисел 2, 3, 5? Эта задача решается по формуле включения и исключения.
Обозначим через




означает, что число делится на 6,





Но чтобы найти, сколько чисел от 1 до


и значит,

Таким образом, 32 числа от 1 до 100 не делятся ни на 2, ни на 3, ни на 5. Эти числа и уцелеют после первых трех шагов процесса Эратосфена. Кроме них останутся сами числа 2, 3 и 5. Всего останется 35 чисел.
А из первой тысячи после первых трех шагов процесса Эратосфена останется 335 чисел. Это следует из того, что в этом случае


Другой метод доказательства
В предыдущем разделе непосредственно установлена связь между задачей Фибоначчи и комбинаторной задачей. Эту связь можно установить и иначе, непосредственно доказав, что число

 |
(7.5) |
что и числа Фибоначчи. В самом деле, возьмем любую


Пусть теперь последовательность оканчивается на 1. Так как двух единиц подряд быть не может, то перед этой единицей стоит нуль. Иными словами, последовательность оканчивается на 01. Остающаяся же после отбрасывания 0 и 1



Таким образом, получено то же самое рекуррентное соотношение. Отсюда еще не вытекает, что числа

Перестановки
При составлении размещений без повторений из
элементов, то они могут отличаться друг от друга лишь порядком входящих в них элементов. Такие расстановки называют перестановками из n элементов, или, короче,
Процесс последовательных разбиений
Для решения комбинаторных задач часто применяют метод, использованный в предыдущем пункте: устанавливают для данной задачи рекуррентное соотношение и показывают, что оно совпадает с рекуррентным соотношением для другой задачи, решение которой нам уже известно. Если при этом совпадают и начальные члены последовательностей в достаточном числе, то обе задачи имеют одинаковые решения.
Применим описанный прием для решения следующей задачи.
Пусть дано некоторое множество из 
Обозначим число способов разбиения для множества из

предметов через

Подсчитаем число процессов в



процессами. По правилу произведения получаем, что

 |
(7.6) |
Таким образом получено рекуррентное соотношение для
Размещения без повторений
Имеется




Рекуррентные соотношения
При решении многих комбинаторных задач пользуются методом сведения данной задачи к задаче, касающейся меньшего числа предметов. Метод сведения к аналогичной задаче для меньшего числа предметов называется методом рекуррентных соотношений (от латинского "recurrere" - "возвращаться").
Понятие рекуррентных соотношений проиллюстрируем классической проблемой, которая была поставлена около 1202 года Леонардо из Пизы, известным как Фибоначчи. Важность чисел Фибоначчи для анализа комбинаторных алгоритмов делает этот пример весьма подходящим.
Фибоначчи поставил задачу в форме рассказа о скорости роста популяции кроликов при следующих предположениях. Все начинается с одной пары кроликов. Каждая пара становится фертильной через месяц, после чего каждая пара рождает новую пару кроликов каждый месяц. Кролики никогда не умирают, и их воспроизводство никогда не прекращается.
Пусть









Объединяя эти равенства, получим следующее рекуррентное соотношение:

 |
(7.1) |
Выбор начальных условий для последовательности чисел Фибоначчи не важен; существенное свойство этой последовательности определяется рекуррентным соотношением. Будем предполагать


Рассмотрим эту задачу немного иначе.
Пара кроликов приносит раз в месяц приплод из двух крольчат (самки и самца), причем новорожденные крольчата через два месяца после рождения уже приносят приплод. Сколько кроликов появится через год, если в начале года была одна пара кроликов?
Из условия задачи следует, что через месяц будет две пары кроликов. Через два месяца приплод даст только первая пара кроликов, и получится 3 пары.
А еще через месяц приплод дадут и исходная пара кроликов, и пара кроликов, появившаяся два месяца тому назад. Поэтому всего будет 5 пар кроликов. Обозначим через
количество пар кроликов по истечении
месяцев будут эти

 | (7.2) |



В частности,

Числа

Найти число
Чтобы установить эту связь, возьмем любую такую последовательность и сопоставим ей пару кроликов по следующему правилу: единицам соответствуют месяцы появления на свет одной из пар "предков" данной пары (включая и исходную), а нулями - все остальные месяцы. Например, последовательность 010010100010 устанавливает такую "генеалогию": сама пара появилась в конце 11-го месяца, ее родители - в конце 7-го месяца, "дед" - в конце 5-го месяца и "прадед" - в конце второго месяца. Исходная пара кроликов тогда зашифровывается последовательностью 000000000000.
Ясно, что при этом ни в одной последовательности не могут стоять две единицы подряд - только что появившаяся пара не может, по условию, принести приплод через месяц. Кроме того, при указанном правиле различным последовательностям отвечают различные пары кроликов, и обратно, две различные пары кроликов всегда имеют разную "генеалогию", так как, по условию, крольчиха дает приплод, состоящий только из одной пары кроликов.
Установленная связь показывает, что число
Докажем теперь, что
 | (7.3) |


Иными словами,




В самом деле,




Равенство (7.3) можно доказать и иначе. Положим

где


легко следует, что
 | (7.4) |



удовлетворяют рекуррентному соотношению


и, вообще,

Сочетания
В тех случаях, когда нас не интересует порядок элементов в комбинации, а интересует лишь ее состав, говорят о сочетаниях. Итак,
элементов называют всевозможные

Формула для числа сочетаний получается из формулы для числа размещений. В самом деле, составим сначала все
элементов, а потом переставим входящие в каждое сочетание элементы всеми возможными способами. При этом получается, что все



Затруднение мажордома"
Бывают комбинаторные задачи, в которых приходится составлять не одно рекуррентное соотношение, а систему соотношений, связывающую несколько последовательностей. Эти соотношения выражают
Задача: "Затруднение мажордома". Однажды мажордом короля Артура обнаружил, что к обеду за круглым столом приглашено 6 пар враждующих рыцарей. Сколькими способами можно рассадить их так, чтобы никакие два врага не сидели рядом?
Если мы найдем какой-то способ рассадки рыцарей, то, пересаживая их по кругу, получим еще 11 способов. Мы не будем сейчас считать различными способы, получающиеся друг из друга такой циклической пересадкой.
Введем следующие обозначения. Пусть число рыцарей равно



Выведем сначала формулу, выражающую




последующие рассуждения теряют силу.
Выясним теперь, сколькими способами можно снова посадить ушедших рыцарей за стол так, чтобы после этого не было одной пары соседей-врагов.
Проще всего посадить их, если за столом рядом сидят две пары врагов. В этом случае один из вновь пришедших садится между рыцарями первой пары, а другой – между рыцарями второй пары. Это можно сделать двумя способами. Но так как число способов рассадки

Пусть теперь рядом сидит только одна пара врагов.
Один из вернувшихся должен сесть между ними. Тогда за столом окажутся




Наконец, пусть никакие два врага не сидели рядом. В этом случае первый рыцарь садится между любыми двумя гостями - это он может сделать


способами. Как уже отмечалось, разработанными случаями исчерпываются все возможности. Поэтому имеет место рекуррентное соотношение
 | (7.7) |
Этого соотношения пока недостаточно, чтобы найти



Предположим, что среди



способами, а так как их еще можно поменять местами, то получится


Наконец, номер ушедшей и вернувшейся пары рыцарей мог быть любым от 1 до
 | (7.8) |
Наконец, разберем случай, когда среди


рыцарей, причем среди них либо не будет ни одной пары врагов-соседей (если новые рыцари не сидят рядом), либо только одна такая пара.
Первый вариант может быть в

способами.
Второй же вариант может быть в

Здесь тоже можно вернуться к исходной компании 4 способами, и мы получаем всего


 | (7.9) |
Мы получили систему рекуррентных соотношений
 | (7.10) |
 | (7.11) |
| (7.12) |
Они справедливы при




Линейные рекуррентные соотношения с постоянными коэффициентами
Для решения рекуррентных соотношений общих правил, вообще говоря, нет. Однако существует весьма часто встречающийся класс соотношений, решаемый единообразным методом. Это - рекуррентные соотношения вида
 |
(8.3) |
где

Сначала рассмотрим, как решаются такие соотношения при

 |
(8.4) |
Решение этих соотношений основано на следующих двух утверждениях.
Если



последовательность

В самом деле, по условию, имеем


Умножим эти равенства на

А это означает, что

Если



является решением рекуррентного соотношения

В самом деле, если




Оно справедливо, так как по условию имеем



также является решением соотношения (8.4). Для доказательства достаточно использовать утверждение (8.4), положив в нем

Из утверждений 1 и 2 вытекает следующее правило решения линейных рекуррентных соотношений второго порядка с постоянными коэффициентами.
Пусть дано рекуррентное соотношение
 |
(8.5) |
Составим квадратное уравнение
|
(8.6) |
которое называется характеристическим для данного соотношения. Если это уравнение имеет два различных корня


Чтобы доказать это правило, заметим сначала, что по утверждению 2





имеет решение при любых

Этими решениями являются


(Случай, когда оба корня уравнения (8.6) совпадут друг с другом, разберем в следующем пункте.)
Пример на доказанное правило.
При изучении чисел Фибоначчи мы пришли к рекуррентному соотношению
 | (8.7) |

Корнями этого квадратного уравнения являются числа

Поэтому общее решение соотношения Фибоначчи имеет вид
 | (8.8) |
вместо





систему уравнений


Отсюда находим, что

 | (8.9) |
Производящие функции
В комбинаторных задачах на подсчет числа объектов при наличии некоторых ограничений искомым решением часто является последовательность




 |
(8.12) |
называемый производящей функцией для данной последовательности. Название формальный ряд для данной последовательности означает, что (8.12) мы трактуем только как удобную запись нашей последовательности - в данном случае несущественно, для каких (действительных или комплексных) значений переменной

мы определим операцию сложения:
 |
(8.13) |
операцию умножения на число (действительное или комплексное):
 |
(8.14) |
и произведение Коши
 |
(8.15) |
где
 |
(8.16) |
Если




 |
(8.17) |
(






и т.д.
Решение рекуррентных соотношений
Будем говорить, что рекуррентное соотношение имеет порядок



рекуррентное соотношение второго порядка, а

элементов последовательности можно задать совершенно произвольно - между ними нет никаких соотношений. Но если первые




Пользуясь рекуррентным соотношением и начальными членами, можно один за другим выписывать члены последовательности, причем рано или поздно получим любой ее член. Однако при этом придется выписать и все предыдущие члены - ведь не узнав их, мы не узнаем и последующих членов. Но во многих случаях нужно узнать только один определенный член последовательности, а остальные не нужны. В этих случаях удобнее иметь явную формулу для

является одним из решений рекуррентного соотношения

В самом деле, общий член этой последовательности имеет вид




Решение рекуррентного соотношения

и путем подбора этих постоянных можно получить любое решение данного соотношения. Например, для соотношения
 |
(8.1) |
общим решением будет
 |
(8.2) |
В самом деле, легко проверить, что последовательность (8.2) обращает (8.1) в тождество. Поэтому нам надо только показать, что любое решение нашего соотношения можно представить в виде (8.2). Но любое решение соотношения (8.1) однозначно определяется значениями


найдутся такие значения




Но легко видеть, что при любых значениях
система уравнений

Случай равных корней характеристического уравнения
Рассмотрим случай, когда оба корня характеристического уравнения совпадают:




Остается только одно произвольное постоянное ; и выбрать его так, чтобы удовлетворить двум начальным условиям






А тогда рекуррентное соотношение имеет такой вид:
 |
(8.10) |
Проверим, что




Значит,

Итак, имеются два решения




Линейные рекуррентные соотношения с постоянными коэффициентами, порядок которых больше двух, решаются таким же способом. Пусть соотношение имеет вид
 |
(8.11) |
Составим характеристическое уравнение

Если все корни


Если же, например,



рекуррентного соотношения (8.11). В общем решении этому корню соответствует часть

Составляя такое выражение для всех корней и складывая их, получаем общее решение соотношения (8.3).
Например, решим рекуррентное соотношение

Характеристическое уравнение в этом случае имеет вид

Решая его, получим корни

Значит, общее решение нашего соотношения имеет следующий вид:

Алгебраические дроби и степенные ряды
При делении многочлена



 |
(9.2) |
Рассмотрим, например, разложение
 |
(9.3) |
Мы не пишем здесь знака равенства, так как не знаем, какой смысл имеет стоящая справа сумма бесконечного числа слагаемых. Чтобы выяснить это, попробуем подставлять в обе части соотношения (9.3) различные значения



Так как мы не умеем складывать бесконечно много слагаемых, попробуем взять сначала одно слагаемое, потом - два, потом - три и так далее слагаемых. Мы получим такие суммы:

эти суммы приближаются к значению

То же самое получится, если вместо






Однако, если взять



Если последовательно складывать члены этого ряда, то получаются суммы 1; 5; 21; 85; … Эти суммы неограниченно увеличиваются и не приближаются к числу
Мы встретились, таким образом, с двумя случаями. Чтобы их различать, введем общее понятие о сходимости и расходимости числового ряда. Пусть задан бесконечный числовой ряд
 |
(9.4) |
Говорят, что бесконечный числовой ряд сходится к числу

стремится к нулю при неограниченном увеличении




В этом случае число


Если не существует числа
Проведенное выше исследование показывает, что


в то время как ряд






и что при




получаем расходящиеся числовые ряды

и

 | (9.5) |
Мы выяснили, таким образом, смысл записи

Она показывает, что для значений

Пусть при делении многочлена
 | (9.6) |




Иными словами, всегда есть область
 | (9.7) |



Отметим еще следующее важное утверждение: функция
не может иметь двух различных разложений в степенные ряды.
Действия над степенными рядами
Перейдем теперь к действиям над степенными рядами. Пусть функции

 |
(9.12) |
 |
(9.13) |
Тогда

Оказывается, что слагаемые в правой части равенства можно переставить и сгруппировать вместе члены с одинаковыми степенями
 |
(9.14) |
Ряд, стоящий в правой части равенства (9.14), называется суммой степенных рядов (9.12) и (9.13).
Посмотрим теперь, как разлагается в степенной ряд произведение функций
 |
(9.15) |
Оказывается, что как и в случае многочленов, ряды, стоящие в правой части равенства (9.15), можно почленно перемножать. Мы опускаем доказательство этого утверждения. Найдем ряд, получающийся после почленного перемножения. Свободный член этого ряда равен






Точно так же вычисляются члены, содержащие

 |
(9.16) |
Ряд, стоящий в правой части равенства (9.16), называется произведением рядов(9.12) и (9.13).
В частности, возводя ряд (9.12) в квадрат, получаем
 |
(9.17) |
Посмотрим теперь, как делят друг на друга степенные ряды. Пусть свободный член ряда (9.13) отличен от нуля. Покажем, что в этом случае существует такой степенной ряд
 |
(9.18) |
что
 |
(9.19) |
Для доказательства перемножим ряды в левой части этого равенства. Мы получим ряд

Для того чтобы этот ряд совпадал с рядом (9.12), необходимо и достаточно, чтобы выполнялись равенства




Эти равенства дают бесконечную систему уравнений для отыскания коэффициентов Из первого уравнения системы получаем


из которого находим, что




Это уравнение разрешимо, поскольку


Деление многочленов
Если заданы два многочлена







Ясно, что процесс деления никогда не закончится ( так же, например, как при обращении числа




причем свободный член
отличен от нуля,

на
 |
(9.1) |
Лишь в случае, когда
Метод рекуррентных соотношений позволяет решать
Метод рекуррентных соотношений позволяет решать многие комбинаторные задачи. Но в целом ряде случаев рекуррентные соотношения довольно трудно составить, а еще труднее решить. Зачастую эти трудности удается обойти, использовав производящие функции. Поскольку понятие производящей функции связано с бесконечными степенными рядами, познакомимся с этими рядами.
Бином Ньютона
Получим производящую функцию для конечной последовательности чисел


и

Эти равенства являются частными случаями более общей формулы, дающей разложение для

 |
(10.4) |
Раскроем скобки в правой части этого равенства, причем будем записывать все множители в том порядке, в котором они нам встретятся. Например,

 |
(10.5) |
а

 |
(10.6) |
Видно, что в формулу (10.5) входят все размещения с повторениями, составленные из букв
букв
и

Отсюда вытекает, что после приведения подобных членов выражение


 |
(10.7) |
Равенство (10.7) принято называть формулой бинома Ньютона. Если положить в этом равенстве

 |
(10.8) |
Мы видим, что


Об едином нелинейном рекуррентном соотношении
При решении задачи о разбиении последовательности мы пришли к рекуррентному соотношению
 |
(10.14) |
где

 |
(10.15) |
Положим
 |
(10.16) |
и возведем



Но по рекуррентному соотношению (10.14),

Значит,

Полученный ряд есть не что иное, как


Для функции

Мы выбрали перед корнем знак минус, так как в противном случае при

мы имели бы


Применение степенных рядов для доказательства тождеств
С помощью степенных рядов можно доказывать многие тождества. Для этого берут некоторую функцию и двумя способами разлагают ее в степенной ряд. Поскольку функция может быть представлена лишь единственным образом в виде степенного ряда, то коэффициенты при одинаковых степенях
Рассмотрим, например, известное нам разложение

Возведя обе части этого разложения в квадрат, получаем
 |
(10.1) |
Если заменить здесь
 |
(10.2) |
Перемножив разложения (10.1) и (10.2), выводим, что
 |
(10.3) |
Очевидно, что коэффициенты при нечетных степенях


Но функцию


А разложение для

 |
(10.4) |
Мы знаем, что никакая функция не может иметь двух различных разложений в степенные ряды. Поэтому коэффициент при
разложении (10.3) должен равняться коэффициенту при
в разложении (10.4). Отсюда вытекает следующее тождество:
